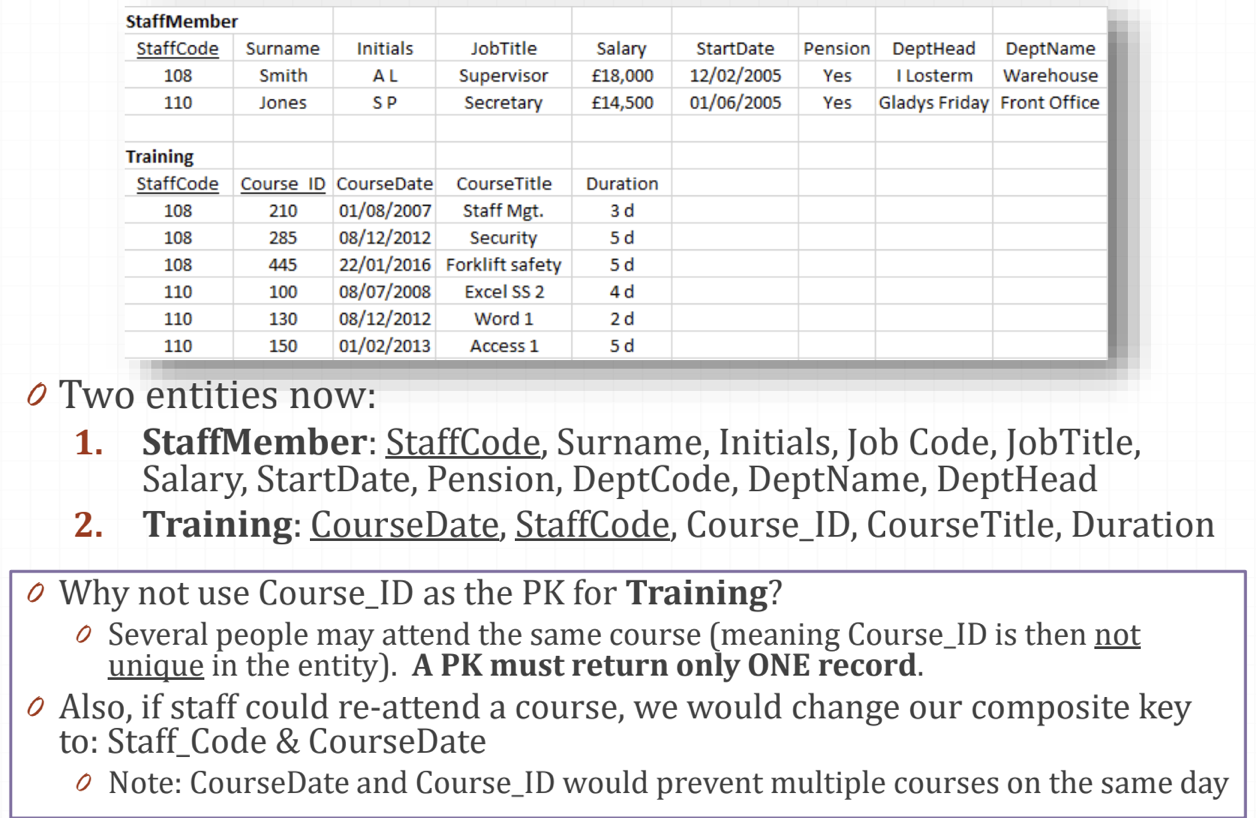
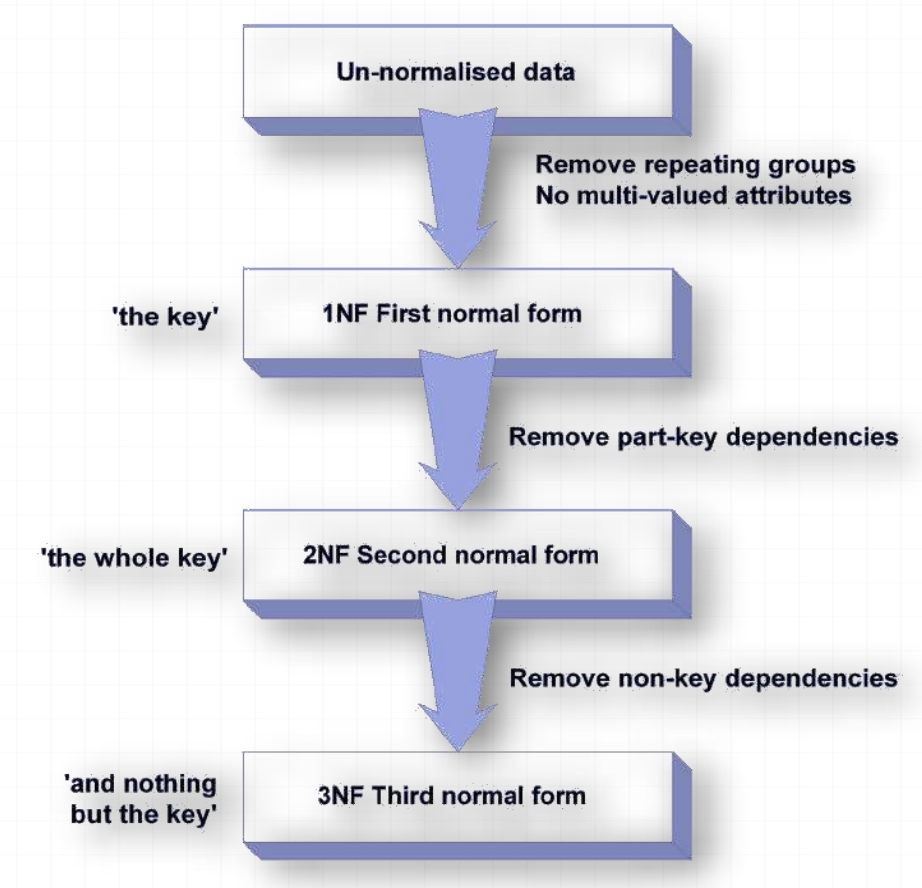
Normalisation
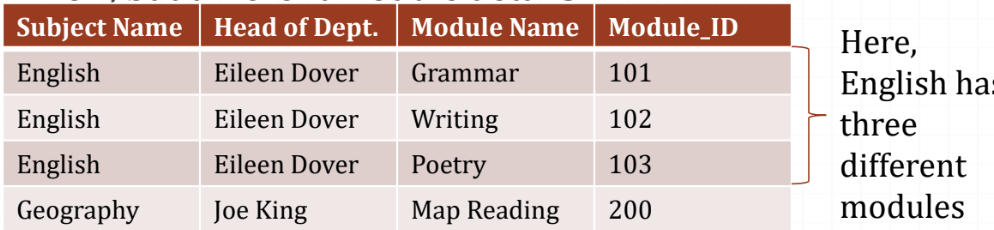
Repeating Groups
- A repeating group is where similar data is repeated within:
- a single entity (e.g. multiple telephone attributes)
- a single tuple (e.g. 2 phone numbers in one attribute)
- Data repeated across tuples is a reaping group
0NF (UNF)
- Unormalised form
- The starting stage before getting to 1st normal form
- UNF is all the entities and attributes before they have been normalised
1NF (First Normal Form)
- Each entity has a unique primary key
- Eliminate any duplicative (repeating) attributes
- Create separate entities for each group of related data and identify each new entity with a primary key and copy the key from the parent table
- (If necessary) Expand any non-atomic data
- Split attributes until the data cannot be broken down further
- Not all data is required to be broken down, unless components will need to be uniquely searched. E.g. Searching for a last name will require it to be separated out of a ‘Name’ attribute.
- Split attributes until the data cannot be broken down further
-
A table is 1NF if:
- every data value in an attribute is atomic
- each record does not contain repeating data
- each row is uniquely identifiable
- Enforced by a primary key
-
Example:
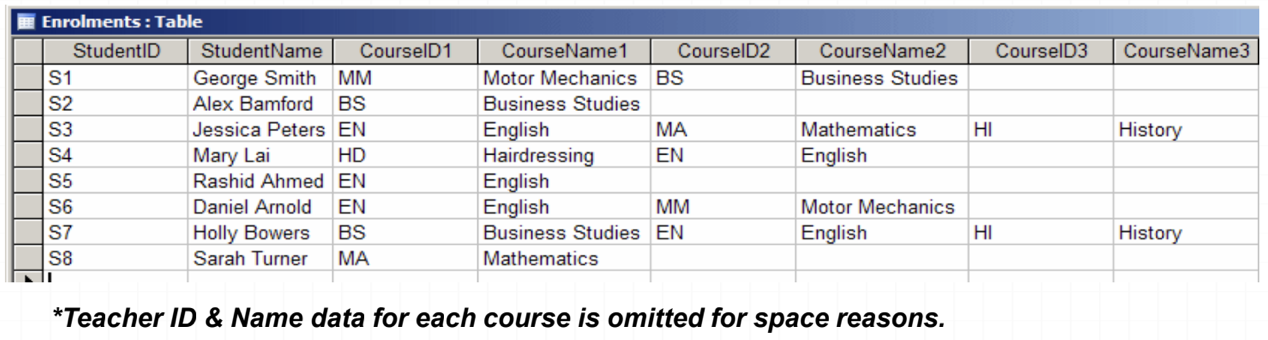
- Where a student is enrolled in fewer than three courses, there are empty cells
- This is wasted storage space in the database
- There is a lot of redundant data. E.g. the course Business Studies has been typed multiple times
- How would you find all the students on the English course?
- You would have to search three fields
- What would happen if a student wanted to enrol on four (or five, or even six) courses?
- The table would have to be re-designed
-